Introduction¶
Training wheels, side rails, and helicopter parent for your Deep Learning projects in PyTorch.
pip install ride
ZERO-boilerplate AI research¶
Ride provides a feature-rich, battle-tested boilerplate, so that you can focus on the model-building and research. 🧪
Out of the box, Ride gives you:
Training and testing methods 🏋️♂️
Checkpointing ✅
Metrics 📈
Finetuning schemes 👌
Feature extraction 📸
Visualisations 👁
Hyperparameter search 📊
Logging 📜
Command-line interface 💻
Multi-gpu, multi-node handling via

… and more
Boilerplate inheritance¶
With Ride, we inject functionality by means of inheritance.
The same way, your network would usually inherit from torch.nn.Module, we can mix in a plethora of functionality by inheriting from the RideModule (which also includes the torch.nn.Module).
In addition, boiler-plate for wiring up optimisers, metrics and datasets can be also mixed in as seen below.
Complete project definition¶
# simple_classifier.py
import torch
import ride
import numpy as np
from .examples import MnistDataset
class SimpleClassifier(
ride.RideModule,
ride.SgdOneCycleOptimizer,
ride.TopKAccuracyMetric(1,3),
MnistDataset,
):
def __init__(self, hparams):
# `self.input_shape` and `self.output_shape` were injected via `MnistDataset`
self.l1 = torch.nn.Linear(np.prod(self.input_shape), self.hparams.hidden_dim)
self.l2 = torch.nn.Linear(self.hparams.hidden_dim, self.output_shape)
def forward(self, x):
x = x.view(x.size(0), -1)
x = torch.relu(self.l1(x))
x = torch.relu(self.l2(x))
return x
@staticmethod
def configs():
c = ride.Configs()
c.add(
name="hidden_dim",
type=int,
default=128,
strategy="choice",
choices=[128, 256, 512, 1024],
description="Number of hidden units.",
)
return c
if __name__ == "__main__":
ride.Main(SimpleClassifier).argparse()
The above is the complete code for a simple classifier on the MNIST dataset.
All of the usual boiler-plate code has been mixed in using multiple inheritance:
RideModuleis a base-module which includespl.LightningModuleand makes some behind-the-scenes python-magic work. For instance, it modifies your__init__function to automatically initiate all the mixins correctly. Moreover, it mixes intraining_step,validation_step, andtest_step.SgdOneCycleOptimizermixes in aconfigure_optimizersfunctionality with SGD and OneCycleLR scheduler.TopKAccuracyMetricadds top1acc and top3acc metrics, which can be used for checkpointing and benchmarking.MnistDatasetmixes intrain_dataloader,val_dataloader, andtest_dataloaderfunctions for the MNIST dataset. Dataset mixins always provideinput_shapeandoutput_shapeattributes, which are handy for defining the networking structure as seen in__init__.
Configs¶
In addition to inheriting lifecycle functions etc., the mixins also add configs to your module (powered by co-rider).
These define all of the configurable (hyper)parameters including their
type
default value
description in plain text (reflected in command-line interface),
choices defines accepted input range
strategy specifies how hyperparameter-search tackles the parameter.
Configs specific to the SimpleClassifier can be added by overloading the configs methods as shown in the example.
The final piece of sorcery is the Main class, which adds a complete command-line interface.
Command-line interface 💻¶
Train and test¶
$ python simple_classifier.py --train --test --learning_rate 0.01 --hidden_dim 256 --max_epochs 1
Example output:
lightning: Global seed set to 123 ride: Running on host HostName ride: ⭐️ View project repository at https://github.com/UserName/project_name/tree/commit_hash ride: Run data is saved locally at /Users/UserName/project_name/logs/run_logs/your_id/version_1 ride: Logging using Tensorboard ride: 💾 Saving /Users/au478108/Projects/ride/logs/run_logs/your_id/version_1/hparams.yaml ride: 🚀 Running training ride: ✅ Checkpointing on val/loss with optimisation direction min lightning: GPU available: False, used: False lightning: TPU available: False, using: 0 TPU cores lightning: | Name | Type | Params -------------------------------- 0 | l1 | Linear | 200 K 1 | l2 | Linear | 2.6 K -------------------------------- 203 K Trainable params 0 Non-trainable params 203 K Total params 0.814 Total estimated model params size (MB) lightning: Global seed set to 123 Epoch 0: 100%|████████| 3751/3751 [00:20<00:00, 184.89it/s, loss=0.785, v_num=9, step_train/loss=0.762] lightning: Epoch 0, global step 3437: val/loss reached 0.77671 (best 0.77671), saving model to "/Users/UserName/project_name/logs/run_logs/your_id/version_1/checkpoints/epoch=0-step=3437.ckpt" as top 1 lightning: Saving latest checkpoint... Epoch 0: 100%|████████| 3751/3751 [00:20<00:00, 184.65it/s, loss=0.785, v_num=9, step_train/loss=0.762] ride: 🚀 Running evaluation on test set Testing: 100%|████████| 625/625 [00:01<00:00, 358.86it/s] ------------------------------------- DATALOADER:0 TEST RESULTS {'loss': 0.7508705258369446, 'test/loss': 0.7508705258369446, 'test/top1acc': 0.7986000180244446, 'test/top3acc': 0.8528000116348267} ------------------------------------- ride: 💾 Saving /Users/UserName/project_name/logs/run_logs/your_id/version_1/test_results.yaml
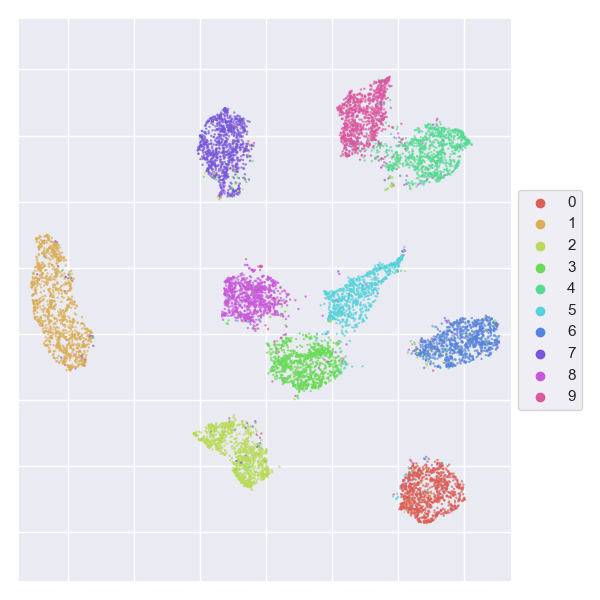
Feature extraction and visualisation¶
Extract features after layer l1 and visualise them with UMAP.
$ python simple_classifier.py --train --test --extract_features_after_layer = "l1" --visualise_features = "umap"
Example output:
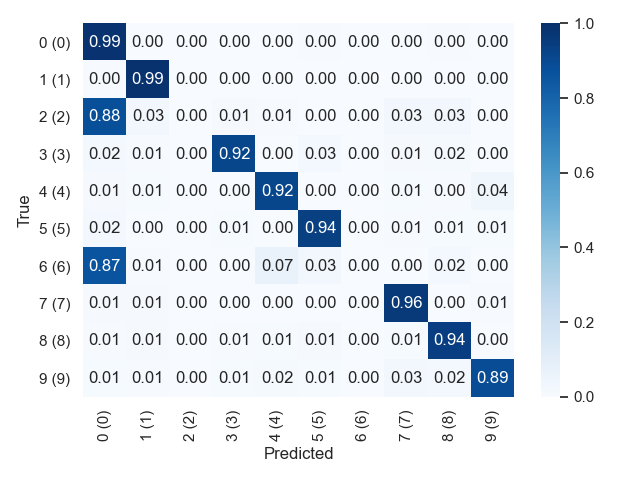
Confusion matrix visualisation¶
Plot the confution matrix for the test set.
$ python simple_classifier.py --train --test --test_confusion_matrix 1
Example output:
Advanced model finetuning¶
Load model and finetune with gradual unfreeze and discriminative learning rates
$ python simple_classifier.py --train --finetune_from_weights your/path.ckpt --unfreeze_layers_initial 1 --unfreeze_epoch_step 1 --unfreeze_from_epoch 0 --discriminative_lr_fraction 0.1
Hyperparameter optimization¶
If we want to perform hyperparameter optimisation across four gpus, we can run:
$ python simple_classifier.py --hparamsearch --gpus 4
Curretly, we use Ray Tune and the ASHA algorithm under the hood.
Profile model¶
You can check the timing and FLOPs of the model with:
$ python simple_classifier.py --profile_model
Example output:
Results: flops: 203530 machine: cpu: architecture: x86_64 cores: physical: 6 total: 12 frequency: 2.60 GHz model: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz gpus: null memory: available: 5.17 GB total: 16.00 GB used: 8.04 GB system: node: d40049 release: 19.6.0 system: Darwin params: 203530 timing: batch_size: 16 num_runs: 10000 on_gpu: false samples_per_second: 88194.303 +/- 17581.377 [20177.049, 113551.377] time_per_sample: 12.031us +/- 3.736us [8.807us, 49.561us]
Additional options¶
For additional configuration options, check out the help:
$ python simple_classifier.py --help
Truncated output:
Flow: Commands that control the top-level flow of the programme. --hparamsearch Run hyperparameter search. The best hyperparameters will be used for subsequent lifecycle methods --train Run model training --validate Run model evaluation on validation set --test Run model evaluation on test set --profile_model Profile the model General: Settings that apply to the programme in general. --id ID Identifier for the run. If not specified, the current timestamp will be used (Default: 202101011337) --seed SEED Global random seed (Default: 123) --logging_backend {tensorboard,wandb} Type of experiment logger (Default: tensorboard) ... Pytorch Lightning: Settings inherited from the pytorch_lightning.Trainer ... --gpus GPUS number of gpus to train on (int) or which GPUs to train on (list or str) applied per node ... Hparamsearch: Settings associated with hyperparameter optimisation ... Module: Settings associated with the Module --loss {mse_loss,l1_loss,nll_loss,cross_entropy,binary_cross_entropy,...} Loss function used during optimisation. (Default: cross_entropy) --batch_size BATCH_SIZE Dataloader batch size. (Default: 64) --num_workers NUM_WORKERS Number of CPU workers to use for dataloading. (Default: 10) --learning_rate LEARNING_RATE Learning rate. (Default: 0.1) --weight_decay WEIGHT_DECAY Weight decay. (Default: 1e-05) --momentum MOMENTUM Momentum. (Default: 0.9) --hidden_dim HIDDEN_DIM {128, 256, 512, 1024} Number of hidden units. (Defualt: 128) --extract_features_after_layer EXTRACT_FEATURES_AFTER_LAYER Layer name after which to extract features. Nested layers may be selected using dot-notation, e.g. `block.subblock.layer1` (Default: ) --visualise_features {,umap,tsne,pca} Visualise extracted features using selected dimensionality reduction method. Visualisations are created only during evaluation. (Default: ) --finetune_from_weights FINETUNE_FROM_WEIGHTS Path to weights to finetune from. Allowed extension include {'.ckpt', '.pyth', '.pth', '.pkl', '.pickle'}. (Default: ) --unfreeze_from_epoch UNFREEZE_FROM_EPOCH Number of epochs to wait before starting gradual unfreeze. If -1, unfreeze is omitted. (Default: -1) --test_confusion_matrix {0,1} Create and save confusion matrix for test data. (Default: 0) ...
Though the above
--helpprintout was truncated for readibility, there’s still a lot going on! The general structure is a follows: First, there are flags for controlling the programme flow (e.g. whether to run hparamsearch or training), then some general parameters (id, seed, etc.), all the parameters from Pytorch Lightning, hparamsearch-related arguments, and finally the Module-specific arguments, which we either in theSimpleClassifieror inherited from the RideModule and mixins.
Environment¶
Per default, Ride projects are oriented around the current working directory and will save logs in the ~/logs folders, and cache to ~/.cache.
This behaviour can be overloaded by changing of the following environment variables (defaults noted):
ROOT_PATH="~/"
CACHE_PATH=".cache"
DATASETS_PATH="datasets" # Dir relative to ROOT_PATH
LOGS_PATH="logs" # Dir relative to ROOT_PATH
RUN_LOGS_PATH="run_logs" # Dir relative to LOGS_PATH
TUNE_LOGS_PATH="tune_logs"# Dir relative to LOGS_PATH
LOG_LEVEL="INFO" # One of "DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"
Examples¶
Library Examples¶
Community Examples¶
Video-based human action recognition:
Skeleton-based human action recognition:
Citation¶
BibTeX¶
If you use Ride for your research and feel like citing it, here’s a BibTex:
@article{hedegaard2021ride,
title={Ride},
author={Lukas Hedegaard},
journal={GitHub. Note: https://github.com/LukasHedegaard/ride},
year={2021}
}
Badge  ¶
¶
.MD
[](https://github.com/LukasHedegaard/ride)
.HTML
<a href="https://github.com/LukasHedegaard/ride">
<img src="https://img.shields.io/badge/Built_to-Ride-643DD9.svg" height="20">
</a>
